如題和各位介紹SQL SERVER中表與表關聯時 , 背後JOIN是怎麼比對資料的。
JOIN簡單分成3種
MERGE JOIN 合併連接
特點 : 兩表都已排序或有索引 , 效能穩定 , 大資料量能快速處理 , 缺點就是需要排序,若沒排序索引會先排序資料才執行。
例子 : 有兩份依名字排序的電話簿,兩邊一起往下比對名字,遇到相同的就配對成功。
HASH JOIN 雜湊連接
特點 : 適合兩邊或單邊都沒排序、沒索引的大資料表 , 若有足夠記憶體可以處理巨量資料(不足可能造成瓶頸)
例子 : 把一份名單先整理成索引表 Hash Table,再拿另一份資料去對照那個索引來找人。
Nested LOOP JOIN 巢狀迴圈連接
特點 : 小表配大表(重點打星號) , 資料少、有索引時速度很快 , 如果資料量大又沒索引,速度會變很慢(執行計畫走錯時可能是災難)
例子 : 拿著一張學生名單(外圈),一個一個學生去班級名冊(內圈)裡找他在哪一班。
這次使用官方提供的範例資料庫AdventureWorks2022 , 以下為bak的連結
https://learn.microsoft.com/zh-tw/sql/samples/adventureworks-install-configure?view=sql-server-ver17&tabs=ssms
實作開始 :
--MERGE JOIN 提示
SELECT D.SalesOrderID,
D.UnitPrice,
H.OrderDate,
H.Status
FROM [Sales].[SalesOrderDetail] D
INNER JOIN [Sales].[SalesOrderHeader] H ON D.SalesOrderID = H.SalesOrderID
OPTION(MERGE JOIN)
--HASH JOIN 提示
SELECT D.SalesOrderID,
D.UnitPrice,
H.OrderDate,
H.Status
FROM [Sales].[SalesOrderDetail] D
INNER JOIN [Sales].[SalesOrderHeader] H ON D.SalesOrderID = H.SalesOrderID
OPTION(HASH JOIN)
--LOOP JOIN 提示
SELECT D.SalesOrderID,
D.UnitPrice,
H.OrderDate,
H.Status
FROM [Sales].[SalesOrderDetail] D
INNER JOIN [Sales].[SalesOrderHeader] H ON D.SalesOrderID = H.SalesOrderID
OPTION(LOOP JOIN)
以下執行計畫圖 , 觀察到效能成本低到高排名依序是
MERGE(合併)-> HASH(雜湊) -> LOOP(巢狀迴圈) ,
執行時間低到高依序是
MERGE(合併) -> HASH(雜湊) -> LOOP(巢狀迴圈) ,
因為這2張表都有已排序的叢集索引供MERGE JOIN所使用 , 效果自然最佳 , 如果遇上沒有索引或是無排序的情況MERGE JOIN效能會大幅下降(得先SORT後才開始比對) , 接著看下一個例子。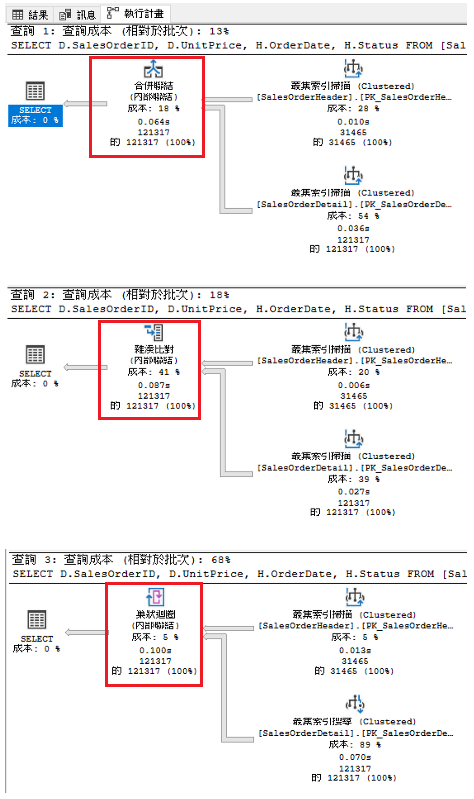
--MERGE JOIN 提示
SELECT P.[BusinessEntityID],
P.[LastName],
C.[CustomerID]
FROM [Person].[Person] P
JOIN [Sales].[Customer] C ON P.BusinessEntityID = C.PersonID
OPTION(MERGE JOIN)
--HASH JOIN 提示
SELECT P.[BusinessEntityID],
P.[LastName],
C.[CustomerID]
FROM [Person].[Person] P
JOIN [Sales].[Customer] C ON P.BusinessEntityID = C.PersonID
OPTION(HASH JOIN)
--LOOP JOIN 提示
SELECT P.[BusinessEntityID],
P.[LastName],
C.[CustomerID]
FROM [Person].[Person] P
JOIN [Sales].[Customer] C ON P.BusinessEntityID = C.PersonID
OPTION(LOOP JOIN)
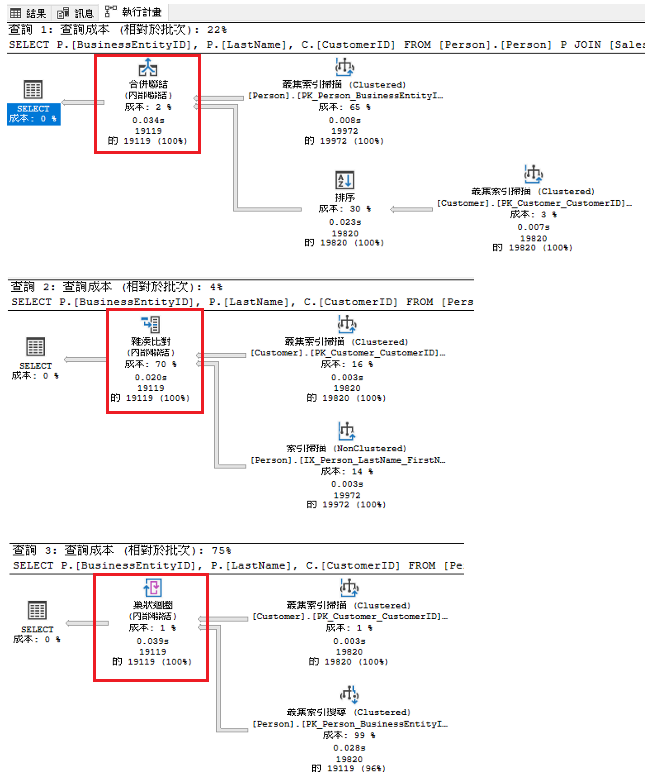
執行計畫圖 , 觀察到效能成本低到高排名依序是
HASH(雜湊) -> MERGE(合併)-> LOOP(巢狀迴圈),
執行時間低到高依序是
HASH(雜湊) -> MERGE(合併)-> LOOP(巢狀迴圈),
各位仔細看MERGE JOIN的執行計畫有多了一項排序的動作後才進行JOIN , 呈上題印證了MERGE JOIN是需要排序資料後才能比對資料 , 有時可能會篩選資料後寫入暫存表再拿暫存表的資料去JOIN , 這時很高的機率就會使用到HASH JOIN策略。
--MERGE JOIN 提示
SELECT P.[LastName],
P.[PersonType],
E.[JobTitle]
FROM [Person].[Person] P
JOIN [HumanResources].[Employee] E ON P.BusinessEntityID = E.BusinessEntityID
OPTION(MERGE JOIN)
--HASH JOIN 提示
SELECT P.[LastName],
P.[PersonType],
E.[JobTitle]
FROM [Person].[Person] P
JOIN [HumanResources].[Employee] E ON P.BusinessEntityID = E.BusinessEntityID
OPTION(HASH JOIN)
--LOOP JOIN 提示
SELECT P.[LastName],
P.[PersonType],
E.[JobTitle]
FROM [Person].[Person] P
JOIN [HumanResources].[Employee] E ON P.BusinessEntityID = E.BusinessEntityID
OPTION(LOOP JOIN)
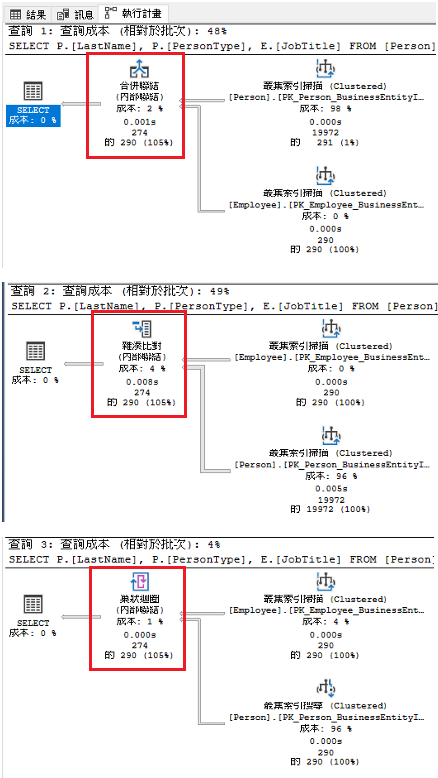
執行計畫圖 , 效能成本低到高排名依序是
LOOP(巢狀迴圈) -> MERGE(合併)-> HASH(雜湊) ,
執行時間3者都差不多 , 在執行計畫中(LOOP JOIN中)上方代表內圈(通常是小表)而下方代表外圈(通常是大表) , 還可以看到Person已經先做了INDEX SEEK 才進行JOIN , 相比之下效能第一當之無愧。
結論 : 了解JOIN策略之後讓我在調教方面上有了基本的效能認知 , 面對大型資料庫很常會有效能瓶頸 , 尤其是在調整SP時 , 千萬不要遇到問題就使用OPTION(RECOMPILE) , 這很浪費系統資源 , 應該先到測試環境試一下找出問題點 , JOIN策略、INDEX走錯、隱轉等等?? , 如有錯誤請指正謝謝。
 混口飯吃的南部人
混口飯吃的南部人
